En la madrugada del lunes la plataforma AWS (Amazon Web Services) comenzó a funcionar en forma incorrecta, lo que genera problemas de conectividad en servicios de todo tipo, ya que AWS es uno de los proveedores de servicios en la nube más usados: un tercio de “la nube” está alojada en servidores de la compañía, según los últimos reportes.
Por “servicios en la nube” se refiere a servicios online alojados en los servidores de Amazon; si esas computadoras fallan, esos servicios quedan inaccesibles, o funcionan incorrectamente.
La caída de AWS es la mayor interrupción de internet desde el fallo de CrowdStrike el año pasado, que afectó a los sistemas tecnológicos de hospitales, bancos y aeropuertos de todo el planeta.
Durante la madrugada la compañía confirmó que el problema estaba en el bloque de servidores denominado US-EAST-1, y que estaba corrigiendo el problema, atribuido a una configuración errónea en los DNS (un servicio que equipara una dirección legible para humanos, como www.lanacion.com.ar, con el número IP específico del servidor que aloja el sitio o servicio online).
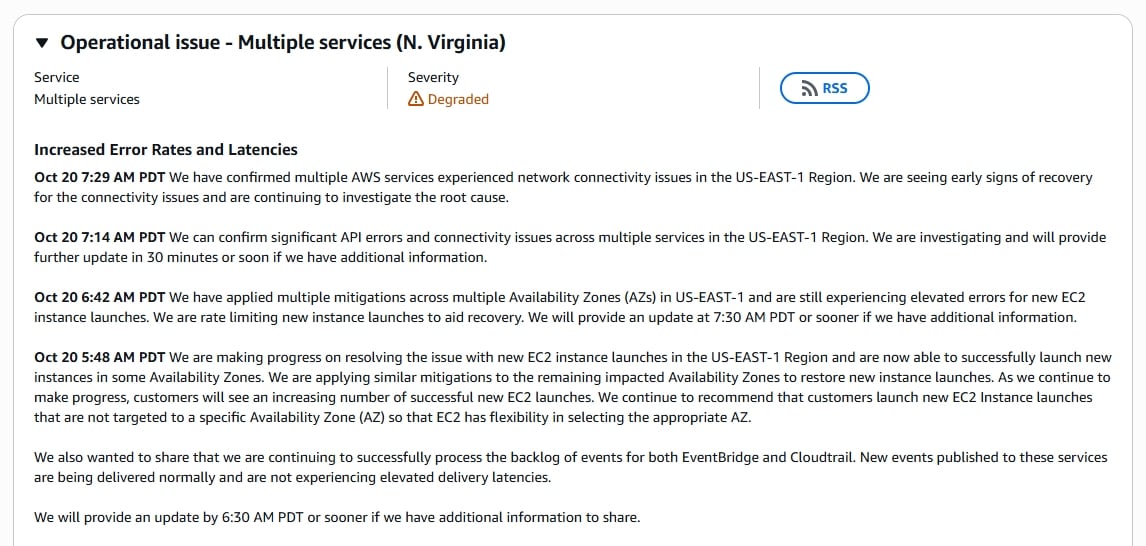
Pero cerca del mediodía del lunes la compañía confirmó que seguía con problemas: “Podemos confirmar errores significativos de API y problemas de conectividad en varios servicios de la región US-EAST-1. Estamos investigando y proporcionaremos más información en 30 minutos o pronto si tenemos más información”, y luego aclaró: “Hemos confirmado que varios servicios de AWS experimentaron problemas de conectividad de red en la región US-EAST-1. Estamos observando indicios de recuperación de los problemas de conectividad y seguimos investigando la causa raíz.”
Así, aunque algunos servicios seguían con un funcionamiento intermitente cerca del mediodía del lunes, la evaluación de la compañía es que el problema está mayormente resuelto, y los servicios alojados en los servidores de la compañía que todavía tienen problemas deberían estabilizarse en las próximas horas.
Junade Ali, ingeniero de software, experto cibernético y miembro de la Institución de Ingeniería y Tecnología, dijo que el problema parecía estar relacionado con uno de los sistemas de red que AWS utiliza para controlar un producto de base de datos.
“Como este problema puede resolverse normalmente de forma centralizada a menos que se identifiquen otros problemas, debería poder mitigarse en las próximas horas”, dijo.
Ookla, propietaria del sitio web de seguimiento de interrupciones Downdetector, dijo que más de 4 millones de usuarios informaron de problemas debido al incidente.
Con información de Reuters